


1.TL;DR
We are writing a series about the performance of BNB Smart Chain and what NodeReal has done to keep improving its performance by reducing the block processing time.
In this chapter, we will talk about the cache (specifically storage cache) which is a traditional but key aspect of performance.
The cache hierarchy can be really complicated in modern computer architecture, you may refer to Wikipedia for a detailed definition of cache. And cache is an abstract concept, it can be a hardware device or a data structure in software.
- As a hardware device, it could be TLB cache, L1 cache, L2 cache for CPU; Or shader cache, texture cache, data cache for GPU…
- As a software data structure, it could be a HashMap, LRU, LFU, ARC, FIFO, QUEUE… These data structures are widely used to store processed data or loaded IO content in memory, so it can be achieved directly without IO access or busy CPU computing.
We will introduce the storage cache of the BSC node in this article, the content includes:
1. The levelized cache hierarchy of BSC storage, i.e. the L1, L2 & L3 cache.
2. The cache patterns we observed on the BSC network.
3. What NodeReal has done to improve storage cache hit rate from ~93 to ~99%.
2. The Levelized Storage Cache
First of all, let’s illustrate the storage access hierarchy with a simple diagram:
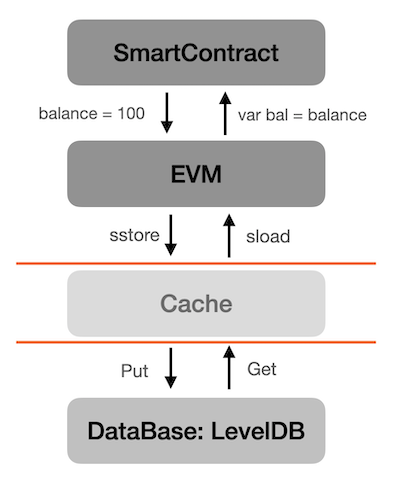
As the above diagram shows, smart contracts can read or write their worldstate easily. The read and write operations of a persistent variable in a smart contract will be compiled into 2 opcodes: sload(read), sstore(write). When EVM detects these 2 opcodes, it will try to load or update the corresponding worldstate item. Actually, the cache is transparent to EVM, EVM only needs to make sure the loaded world state is accurate, it doesn’t care about the source of the data.
The cache component is simplified in the above diagram, as a matter of fact, it is a bit complicated. It is a levelize cache shown in the following diagram.
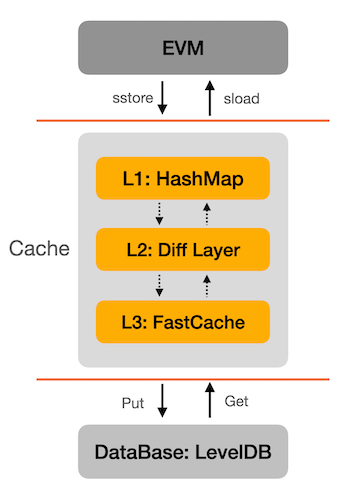
L1 cache: to hold the states that are accessed by the current block.
L2 cache: to hold the states that were updated in the past few blocks, i.e. the past 128 blocks by default.
L3 cache: to hold the even older states that were already flushed into disk.
L1: HashMap
L1 cache is always the most efficient cache with a relatively small cache size. To the BSC client, L1 cache is used to store the temporary data within a block, which means its lifecycle is bound to a single block. When the block process is completed, then its L1 cache is released.
And internal data structure of the L1 cache is a HashMap, it is efficient when the size is small, the query cost could be O(1).
L2: Diff Layer
When L1 cache is missed, it will try to get the state from L2 cache, which is a bloom filtered data structure. Diff layer is a mechanism which is introduced by the Ethereum community mainly to support fast state iteration of the most recent blocks, may refer: Ask about Geth: Snapshot acceleration for detail.
As the name “Diff Layer” suggests, it keeps all the changes that a block made to the universal world state. By default, it will have 128 layers, each layer corresponding to a block, which means it contains the updated state of the latest 128 blocks. Any state change occurring within the block will be recorded in the layer, e.g. account nonce change, balance change or KV update of a contract.
L2 cache only keeps the changed state of the most recent blocks and it uses BloomFilter algorithm which can easily detect if a state isn't included in the layer.
L3: Fast Cache
If L2 cache is missed too, i.e. the state has not been updated during the recent blocks, it will try to get it from L3 cache. The data structure of the L3 cache is a huge RingBuffer with components of bucket & chunk. The size of the L3 cache is configurable and it could be several gigabytes.
The advantage of L3 cache is that it is very large and unlike L1 or L2 cache, it is persistent, the ring buffer structure allows memory reuse, so L3 cache has no GC overhead. Besides, it is concurrently safe and very friendly to the aligned 32 Byte Key/Value slot of EVM.
3. Cache Hit Rate On BSC
We did some profiles on the cache hit rate on BSC, in fact it ranges for different block patterns; how long the node has been running; its configured cache size…
Since L1 uses HashMap cache for a single block, its size is not configurable; L2 is difflayer with a default depth of 128 layers, it is configurable but it doesn’t have a significant effect on cache hit rate, so we keep it by default; So the only related option we set is the cache size of L3 cache, which is 1600MB in our test.
On Start Up
We did a profile on BSC node start-up, here is the result.
The total cost of state access takes ~63% of block execution time in this case. Most of the items are hit in L1 cache, ~74% here and it takes ~20% of block execution time. Only a few items are hit in the L2 cache, ~3% here and it takes ~3% of block execution time. And ~14% items are hit in the L3 cache which takes ~2% of block execution time.
And the cache miss rate is ~9%, these items have to be loaded from disk, which is very expensive, it takes ~38% of block execution time.

After Long Run
We did another profile on the same BSC node after running for ~20 hours, the result showed no big difference except a slightly higher L3 cache hit rate and slightly lower disk IO rate. The total state access cost is ~58% in this case.

4. Our Work And Benefits
NodeReal approached several methods to make the cache more efficient, while the most effective methods could be summarized as “StatePrefetch” and “Shared L1 Cache”.
State Prefetch
This optimization is straightforward and easy to understand as shown by the following diagram.

When a block is to be processed in full sync mode or to be mined in mining mode, we will start N threads to do state prefetch. Transactions of a block or TxPool would be distributed to the prefetch threads as long as they are hungry. And each thread would just execute the transaction and discard the execution results. It helps preload items from disk to cache, specifically the items are loaded into L3 cache, which is a global shared cache.
Although the implementation for full sync mode and miner mode has some differences, they all benefit a lot from the increased cache hit rate.
Cache Level 1.5: Shared Pool
As the previous “State Prefetch” described, it preloads items into L3 cache, which is the lowest cache in the current cache hierarchy. It is not that efficient, since EVM needs to access L1 and L2 before accessing L3.
We introduce a new concept L1.5 cache here, which actually is a shared pool.
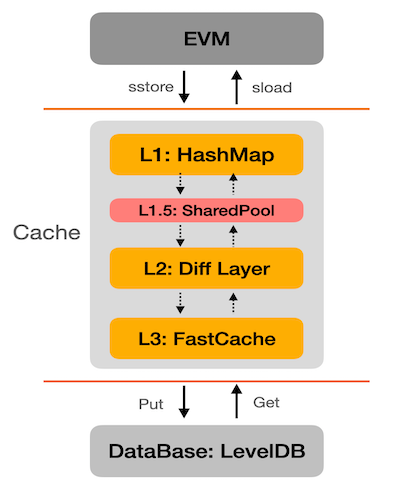
With the shared pool, these concurrently running state prefetch threads share origin storage with the main thread. The origin storage is actually a lower part of L1 cache, it records the unchanged items that are accessed by EVM, i.e. the unchanged KV pair of the contract’s world state, so we name it “Level 1.5 Cache”. By this way, the prefetched items can be directly loaded into the L1.5 cache and the main thread no longer needs to access the L2&L3 cache anymore.
The Benefits
With these cache optimizations, the total cache hit rate increased from ~93% to ~99%, actually many of the blocks no longer need to access disk IO in the main thread any more.
We set up a BSC full node to test the performance benefit, the result is shown by the following diagram. It is a standard metric diagram to show the cost of block processing of the BSC full node.
To clarify it, we upgraded the node in the middle to apply our improvements, the glitch in the diagram was caused by the node upgradation.
- Before upgrading, the cost of block processing on this node is ~150ms.
- After upgradation, the block processing cost has been reduced to ~84ms, which is a ~44% performance increase.
Although the performance benefit ranges for different block patterns, the block processing cost was reduced by 30% -> 40% for most cases, which is really a big improvement.

Celebrate 1 Year of NodeReal with Special Promotion
NodeReal turns 1 year soon! We’d love to take this opportunity to thank all of you who have supported us along the way. Here’s the celebration filled with 2 month of product promotion, in-person meetups, giveaways, and more! Read more HERE.

About NodeReal
NodeReal is a one-stop blockchain infrastructure and service provider that embraces the high-speed blockchain era and empowers developers by “Make your Web3 Real”. We provide scalable, reliable, and efficient blockchain solutions for everyone, aiming to support the adoption, growth, and long-term success of the Web3 ecosystem.
Join Our Community
Join our community to learn more about NodeReal and stay up to date!